When LLMs feast on social
How social platforms will reign when the static web goes stale

The clock on free training data is ticking. By 2028, we might start to run out. In response, LLM labs will increasingly turn to the only renewable source of fresh, conversational content: social.
I predict that within five years (maybe sooner), 30% of new tokens fed into frontier models will come from licensed or unlicensed social streams, not web crawls. Historically, social has been a less ideal ground for harvesting because of walled data gardens: it’s been more promising to keep data internal than to license it out. This is changing, however, as social platforms realize the price of relevance: staying within a walled garden means risking not showing up in LLM conversation (and thus missing consumer eyeballs).
Here’s how I expect social to shape model behavior over the next few years:
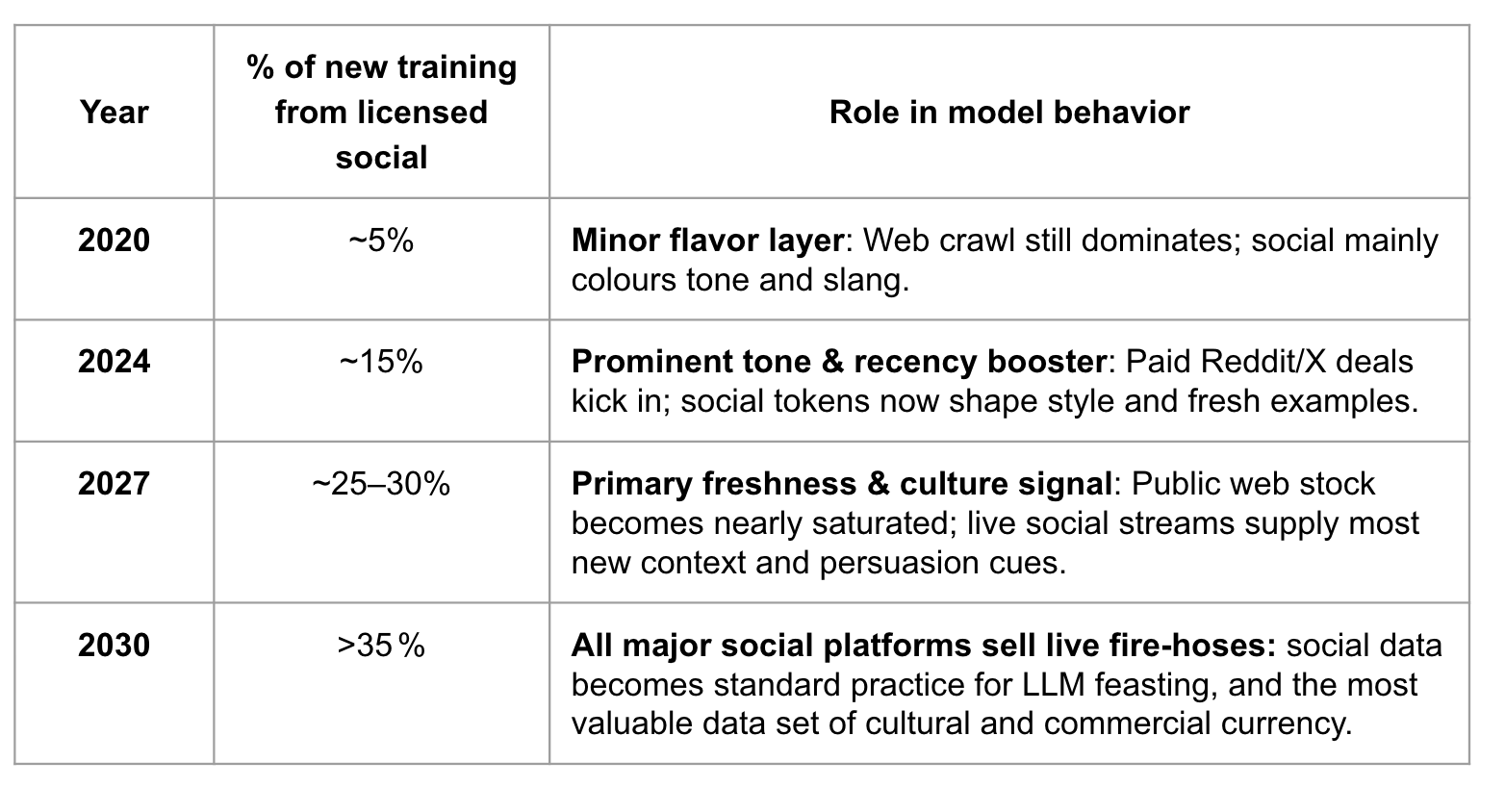
Where social beats the static web
Real‑time relevance: Licensed social streams refresh within hours, while Common Crawl snapshots can lag 35–90 days. New signals land in LLMs much faster.
Conversational DNA: Social is inherently conversational, which helps LLMs understand how humans interact in real time. In a 2024 test by Anthropic, Reddit‑fine‑tuned models scored 15 % higher on dialogue helpfulness than blog‑only baselines.
Long‑tail depth: Web pages usually don’t capture the long tail of human conversation. Reddit and Twitter solve this by injecting niche vocabulary the mainstream web lacks.
Embedded quality signals: Social cues make it easier for models to tell what’s good content and what’s not. Scale AI will be able to estimate up‑votes and watch time data, materially cutting labeling costs vs raw web text.
Licensable freshness: Reddit’s 2024 S‑1 shows us that data‑licensing already drives 9 % of revenue—financial incentive to keep feeds clean and current. I expect this to become a major driver of profits for social platforms in the coming years.
Where each social platform has an edge
Assuming we do move toward a future where social platforms eagerly license at least some portion data to LLMs (there’s no world where they don’t), every platform will start to determine its unique strengths and begin to segment and price that data. Reddit, for example, has long been a source of long-form consumer deliberation, whereas Youtube spikes on influencer authority and educational depth.
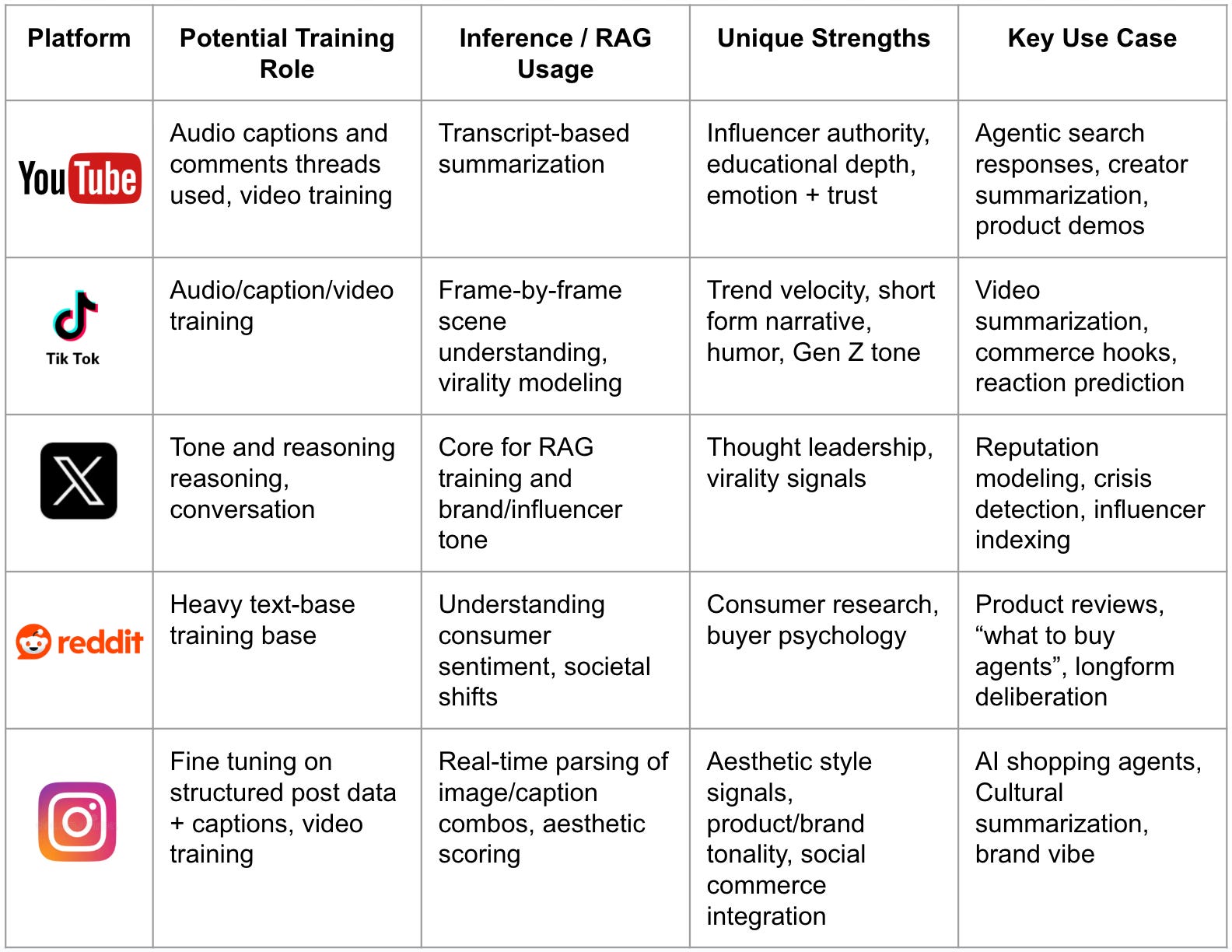
How social data gets priced for LLMs
We’re in early innings of pricing social data for LLMs, but early models (some still speculative) are starting to emerge.
Tiered fire hose APIs (live): paid data streams where platforms meter access by volume and freshness, charging more for higher-traffic or real-time content tiers
This model will be loved by Reddit and text-centric platforms like Stack Exchange (and probably public Discord channels soon). Highly structured text-based data lends itself well to the fire hose format because it’s easy to charge by volume and freshness. We’ll probably see this start to mimi cloud storage pricing over time, with high engagement niches commanding multiples of the baseline. Reddit’s S-1 hints strongly at further development here.
Usage-based transcript feeds (live): labs pay per minute (or per token) of caption data they pull.
TikTok and YouTube will likely monetize this way. Because video files are heavy and variable, charging per minute or token lets labs pay only for what they pull. Any place where a SKU is tagged will likely command a premium over time (more on this later!) YouTube captions are already available via data brokers, and TikTok’s open platform ships free transcripts.
Revenue share on downstream revenue (speculative): Instead of charging per token, social platforms will take a small cut (1-3% maybe) of any revenue an LLM product earns using its data. This lets platforms earn more when their data powers high‑value transactions.
Could be a prime model for Twitter and Substack. Because raw tweets or Substack posts are already plain text (cheap to serve to labs), Twitter and Substack can afford to take a small slice of whatever money an agent makes. The same likely won’t work for YouTube or TikTok because of data processing costs.
Pay-per-token brand safe feeds (speculative): Meta’s Scale partnership sets the stage for this. Scale could filter toxicity, IP flags, and duplicates so Meta can sell a “green‑lit” text and images. Brand‑sensitive buyers would likely pay extra for guaranteed safe, high‑quality tokens.
This is a home run for Reels and even Threads in the short term. Over time I won’t be surprised to see this pricing model creep into other platforms by virtue of other partnerships.
Rank-boost auctions (speculative): Similar to Google AdWords or Amazon Sponsored Products, I can imagine an auction system developing over time whereby brands bid in real time to have their image, post, clip, or link ranked higher.
TikTok and Reddit already rank short posts algorithmically, so this would be a natural extension for them. They could bump their content a few slots higher in an agent’s list just by twisting the monetization knob they already use for ads.
Startup Opportunities
I’ve been thinking a lot about opportunities for startups given the inevitable shift to social data being sold. Long story short — there are myriad huge big companies to be built. That said, it’s obviously much harder and riskier to build for social than it is for the static web. Here are a few threads to pull on:
Answer Engine Optimization for social: This one is probably the most obvious. Build a new Profound or Bluefish, but focus it on social. Brands can’t see or shape how TikTok, Reddit, X content is quoted in ChatGPT, Claude, Gemini — I want someone to build the solution so that they can.
Snowflake for social feeds: I’m imagining this as a a cloud warehouse layer that ingests raw data from multiple social-platform APIs (Reddit fire-hose, TikTok transcript feed, X tweet stream, etc.), normalizes them into a single, query-ready schema, and then lets LLM builders or analytics teams easily pull any slice.
Doubleclick-like ad router: A platform that watches every ranking‑boost auction (Amazon sponsored products, TikTok spark ads, future Reddit/TikTok citation bids) and reallocates dollars to the highest marginal ROAS in real time. The future world of data permissions might make this difficult, but someone will build a version.
Final word
Social streams are fast becoming the fuel that powers tomorrow’s LLMs. Brands, investors, and builders will need to start treating social posts as first‑class training ground. The social gold rush is just beginning, and it requires new infrastructure. Those who normalize, label, and monetize social data stand to capture the most durable value.